
Hello and welcome to my little nock of the internet. Here I have my blog which mainly contain posts about tech, the outdoors, cooking, and some times mead brewing.
A bit of background information before you step into my world of crazy. I am Lars, a.k.a. looopTools, a Software Engineer living in East Jutland, Denmark. I have 10+ years of experience from industry mainly through student positions, but also as self-employed consultant, or full-time employee. I mainly work in low-level user space, high-level kernel space, and storage systems in general. Besides research and software development, I also love the outdoors and try to go out as often as possible (not enough at the moment) and I am an aspiring author currently working on a few different novels. I also dabble in being a more advance home cook and baker, which you may see some posts about. Finally I like the ancient art of brewing mead, a.k.a. honey wine, and experiment with different flavour combinations and ageing times.
Printing via smbclient on Linux command line
After I updated to Fedora 32, my life with my Dell XPS 15” work laptop became so much easier. No random boot locks or I do not want to connect to that Bluetooth device problems. But one thing broke, and that was printing using printers connected through a SAMBA server.
There are a couple of ways to solve this, either go CUPS or run the program smbclient straight from the command line and to be honest, the later speaks to me on a primal level.
Running the client is relatively easy; we simply need to type the command:
smbclient <SERVER>/<PRINTER> -U <USER> -W <DOMAIN> -c print <FILE>
Where <SERVER> is the URL for the SAMBA server, <PRINTER> is the name of the printer you want to print from and more specifically the name of the printer on the SAMBA server. <USER> is your username for that SAMBA server, <DOMAIN> is the work-group domain of your user on the SAMBA server, and <FILE> is the name of the file you want to print.
Okay, it may not be simple, and you have to remember all those details.
Next, what about print settings like printing a duplex?
Well, for that you need another tool, and the one I found works best is pdftops.
With this pdftops you can change the format of the file you want to print, if you want to change an A4 document to duplex, you will need to run pdftops using the following parameters:
pdftops --paper A4 -duplex <INPUT> <OUTPUT>
Where <INPUT> is the path to the input file, I have tested with .odt and .pdf files, and <OUTPUT> is the path of the generate postscript file.
Yes, it generates an additional file.
Then you will run the smbclient command with the output file as <FILE> input.
But that is a lot of work, so can we script our self out of this?
Well, naturally, my young padawan we can!
So first, what do we need? Well, we need to be able to call systems command. What else? Well nothing really, but it would be nice not to have to remember the server URL, printer names, and also where the print is. Okay, seems fair, what scripting/programming language do we use? Well, whatever we want and for this example let us go with Python and let us use a JSON file to keep information on the server, printers, and more.
Let us start with the JSON file and let us assume it has this format:
{
"server": "SERVER_URL",
"domain": "DOMAIN",
"printers": [
{
"name": "PRINTER_NAME",
"location": "WHERE IS THIS THING"
}
]
}
Here printers is a list of the printers you want to be able to print from.
Remember every time you have to add a new printer, and you simply add the information to the JSON file.
I have not included the username for security reasons, so you will have to type the username and password every time you run the script.
Additionally, I will assume that the first printer in the list is our default printer.
So first, how do we list printers?
import json
configFilePath = 'PATH_TO_CONFIG_FILE'
def listPrinters():
with open(configFilePath, 'r') as configFile:
printers = (json.loads(configFile))['printers']
for index, printer in enumerate(printers):
print('{!s}: {!s} - ${!s}'.format(index, printer['name'], printer['location']))
So how do we select a printer? Well notice how I printed the index of the printer, let us use that index, and remember how I assumed that default printer was the first in the printers list.
def getPrinter(index=0):
with open(configFilePath, 'r') as configFile:
return ((json.loads(configFile))['printers'])[0]['name']
Okay, now we can get the printer information that we need.
So now how do we make a function for running the duplex command?
Here I prefer to use the subprocess for tasks like this, so we will define a function that takes a file and make a Postscript version, in the same path as the input file.
We will assume for now that we only handle A4 paper documents.
import os
import subprocess
def generateDuplex(file):
psFile = '{!s}.ps'.format(os.path.splitext(file)[0])
subrocess.call(['pdftops', '-paper', 'A4', '-duplex', file, psFile], encoding='utf-8')
return psFile
This creates the Postscript file with the same name as the input file but with a .ps as an extension.
As a state, the output file will be created in the same directory as the input file, so you may want to clean this up after print.
Next step is to print the file, right? Yes, but how do we get the server and the domain? Like all the rest of the configurations, I just like having a function for it. So let us make that one quickly.
def getServerAndDomain():
with open(configFilePath) as configFile:
data = json.loads(configFile)
return data['server'], data['domain']
Now we are ready to print, and we will again use subprocess to call the system command, this time for smbclient.
import shlex
def printDoc(printer, user, file):
server, domain = getServerAndDomain()
subprocess.call(['smbclient', '{!s}{!s}'.format(server, printer),
'-U', user, '-W', domain, '-c', 'print ' + shlex.quote(file)], encoding='utf-8')
I think a few comments are needed here.
First, what does shlex.quote do?
It fix quotations around the file name for us, so we do not have to handle it.
Secondly, I do not check the output of the smbclient call to see if it succeed.
I should do that, and it is in the future plans, right now I just needed to get the script to work.
But it is fairly easy to get the response, and we would use subprocess.check_call(...) to get the needed information.
Finally, where does the user come from?
Well, where does the printer come from?
Those are command-line arguments, which are given by you!
Now let us make the entry point part of the script.
To handle user inputs, I will use the argparse package, and I will explain this part of the code in, well, parts.
First, we set up the argument parser and the inputs it should be able to handle, as shown in the code block below.
Now a few things that have always annoyed me with argparse was that I could not find a way to provide an argument after the argument name.
As an example, when listing printers, I do not want to have to type python print_doc --printers 1.
I just want to type python print_doc --printers.
During the development of this script, I talked to a friend about this, and he informed me about action='store_true' parameter to argparse which I was unaware off.
I may have missed while I read the documentation.
So as --printers and --duplex do not need an input parameter, we configure these two in that way.
import argparse
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--printer', '-p', help='set the printer')
parser.add_argument('--document', help='set the documnet')
parser.add_argument('--user', '-u', help='set the user')
parser.add_argument('--duplex', '-d', help='set the user', action='store_true')
parser.add_argument('--printers', help='print list of all printers', action='store_true')
args = parser.parse_args()
Next, I will assume that --printers are run just to list printers, and no other parameters should be acted upon if that argument is present and only list the printers.
import sys
if args.printers:
listPrinters()
sys.exit(1)
Next, if we are not looking for printers, we check for the user and document.
if not args.document:
print('You have not provided a document to print')
system.exit(1)
if not args.user:
print('You have not provided a user')
system.exit(1)
Next, we select the printer; if we provide no printer, we choose the default printer.
printer = ``
if args.printer:
printer = getPrinter(int(args.printer))
else:
printer = getPrinter()
Next, we check for enabled duplex and generate the duplex version of the document if needed. We keep the path of the document, such that we can replace it with the duplex document path if needed.
document = args.document
if args.duplex:
document = generateDuplex(document)
Finally, we print the document and remove the duplex version if duplex was enabled.
printDoc(printer, args.user, document)
if args.duplex:
subprocess.call(['rm', document], encoding='utf-8')
So now we can print using this script by typing python SCRIPT_NAME.py -u <USERNAME> --document <PATH_TO_DOCUMENT> if want to enable duplex python SCRIPT_NAME.py -u <USERNAME> --document <PATH_TO_DOCUMENT> -d, and if we want to set a printer python SCRIPT_NAME.py -u <USERNAME> --document <PATH_TO_DOCUMENT> -p <PRINTER_NAME>.
The printDoc will prompt you for your user name if needed.
Now finally if we want to be fancy and not have to type python <PATH_TO_SCRIPT> every time we print.
But want to type, let us say, smbprint instead, we make an alias in our Terminal configuration.
The name of the configuration file varies, but the command we add should be structure the same for BASH, ZSH, and most other common terminals.
alias smbprint="python <PATH_TO_SCRIPT>"
This is how I handle the print using SAMBA printers problem, that has come with Fedora 32, for me. If you want the full script, I have made it available on GitLab, and the version I have presented in this post is tagged as 1.0.0.
Future plans
I have a few plans and dreams for this script.
- Enable other paper sizes
- Change document orientation
- Check the output from subprocess call to
smbclient - Get a list of printers from the SAMBA server
Known bugs
There is one known bug and which is that some files with white space(s) in their name cause a problem with the print statement.
I have the issue both with the script and the raw smbclient command.
My backup setup
I read this tweet yesterday and thought it was interesting how everything could be lost? Who would put every egg in a single basket, and then I read the comments. Some asked me for my backup setup, and I was even requested to do a blog post about my setup, so here is the blog post.
First of my systems are split into two, macOS and Linux machines, this “plays” into part of my setup.
Local Backup
For both macOS and Linux machines, I have full systems backups locally on external hard drives, where each device has a 4TB hard drive.
For the backup up itself, I wanted something that did it automatically, and so I didn’t have to care about it.
On macOS, the obvious solution to this is Timemachine which I have been using since it was introduced in Mac OS X Leopard, and it has saved my buttocks a few times.
Timemachine takes a system “snapshot”, only the first copy is a full snapshot, after that it only copies changes, which is good as it saves storage.
With Linux, I was for a long time looking for something similar but could find a suitable solution and therefore used cron job and dd to take a disk snapshot and then used gzip to compress it and store it on an external disk. That is pretty cumbersome and annoying.
But last year I found the tool Timeshift (github) which is an “alternative” to Timemachine, but for Linux, it does close to the same job and is easy to use.
The benefit of both Timemachine and Timeshift (and cron jobs) is configured to take a system backup every hour.
Meaning that I have a continuous backup of my systems, with the newest data.
Another benefit of both Timemachine and Timeshift if that you can use the backups to install new machines, I have used this feature a couple of times, and it takes the hassle away of remembering every tool you have installed.
Remote Backup
In addition to my Timemachine and Timeshift backups, I also have a remote server setup which I backup to once a week. I have set up calendar events to remind me to do it because I do not have this running on a schedule as I have with the local backups. Read: I still haven’t found a good way to do it on schedule.
On Linux here I still use dd and gzip on mac it is a bit more cumbersome, and I do not take a full system snapshot, I take a copy of my user folder and gzip it.
In both, I encrypt the data after compression, just for safety.
Cloud Back up
In addition to this, I also have a cloud backup of my pictures documents and other stuff. On macOS I use iCloud for this, it is convenient to select what folders I want to sync (to be honest, I just sync most of my user folder).
On Linux, it is a bit more annoying, because I have found a useful tool for it to work like iCloud.
What I have done is to set up Dropbox on my Linux machine and then a cron job runs once every 5 hours (my devices are almost always on) and use rsync to copy the content of the home folder to Dropbox.
I know that there are tools that try to mimic iCloud sync, but then once I have tried, failed on me.
Password
The keys to the castle or just passwords, I have locally in two locations on macOS and one on Linux, and then three times and twice in the cloud. Locally on both, I use KeePassXC as a password manager and have local password database, on both Mac and Linux I sync this file to Dropbox, first cloud backup. On macOS, I also use the build Keychain Access app, which keeps both a local copy and sync to iCloud (second cloud backup). Finally, on both macOS and Linux I use Firefox Lockwise for password and accounts as well.
Yes, I do replicate my accounts across all three password managers, because I have tried that 1Password has failed on me previously, and that is not something I want to try again.
Setup overview
To visualise my setup I have made a small “diagram” of the setup:
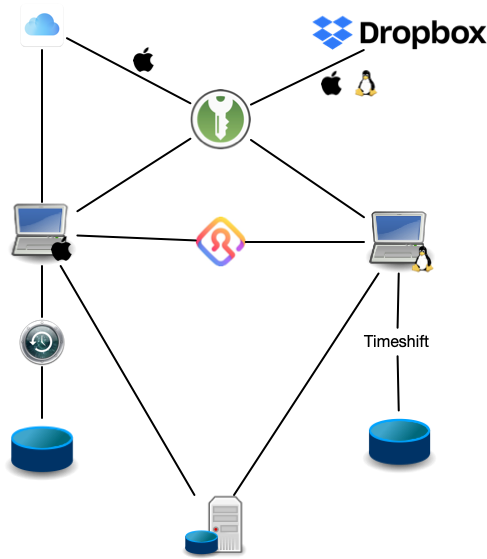
Future plans
Though I am pretty happy with my backup system at the moment, there is room for improvement. One of the things I want to add is one maybe two local NAS, running FreeNAS which will work with Timemachine and Timeshift and another “remote” backup as well. I want to run this using RAID, preferably 5 or 6.
Testing backups
A backup is not worth anything if you do not know if it works. Therefore you need to test them. For macOS I have an older mac laying around I use for testing my mac backups. For Linux, I spawn a virtual machine a create it using the backup, and from time to time I will install on an older device to check if I can make a full system restore on physical hardware as well.
Closing remarks
People may see my backup systems as overkill, but as someone who works on researching storage systems and have worked on cloud storage system my self, I know that your backups backup should have a backup and that is why my system is so complicated.
My main issue with my overall setup is energy consumption. I would like to find a way to reduce that significantly. One thing I could do is to switch from hard drives to solid-state drives, but that will not cause a significant enough reduction. Additionally, I am also looking at finding lower power consuming part for the FreeNAS based NAS I plan to build.
Is it a good idea to be a student programmer?
One of the questions I get most from new students and students that are one year into their studies which are not related to the topic I am teaching is: Do you think I am ready to be student programmer or something very similar. For some time, I wondered why this was until I talked with a former fellow student who has had a hard time getting a job after graduation. Not because he is a bad programmer or software engineer, he is quite good, but because he lacked experience. He was the type that focused 100% on his studies and did not believe he had time enough to be a student programmer. But this had been a significant problem because he did not want (in his words) a job in a consultancy company that hires a lot of new graduates and develop boring stuff. He wanted a job in machine learning and/or computer vision. But every place he applied, he did not get the job, and the main reasoning from the company was his lack of experience. This made him regret not being a student programmer so that he could have gathered some experience during our studies. I sit on the other side of the spectrum, having had student developer jobs or full-time developer jobs throughout my education and have accumulated “a lot of experience” due to this. So it got me thinking, is it a good idea to be a student developer? And if yes, what advice do I have for students who would like to follow this?
Well first of is it a good idea? I have often questioned this. From my perspective, it comes down to a work/life balance. Can you handle both your study and work, will still having time to see your relatives, friends, and have some time to yourself? This is the key for me.
- You study must be the priority
- You need some leisure time
If you decide to study, then that is your primary job and therefore, should be the focus. Removing to much focus from your study will have a negative impact on your results or at least that is my own experience and what I have observed amongst other students. You study to be able to get the job you want in the end (hopefully) and therefore you should put great efforts into doing your best. Now, I know that in Denmark we are incredibly privileged by having our SU (student support) which should cover housing and food, which allows us to focus on studying and that students in other countries do not have this privileged. But I still believe my point of view to be valid in those situations, though much harder to balance. Next, if you overwork yourself weekly (take that from someone who did), you will burn out. Young people tend to say; that will not happen to me… and then it does. This will affect, not just on your study and work life, but also your private life. You can lose connections with friends and family, and you can become extremely unlikable. Which can spiral you down a dark path where you feel alone and do not know how to cope with anything and then the circle goes. This is my personal experience. If you believe you can keep the focus on your studies and have a work/life balance, then I think a student programmer position can be really good.
BUT! There is always a but.
Having a student programmer position is only beneficial if you learn something and if you feel like you are contributing something.
So let us move into the advice section.
First, are you too green?
What I mean is, if you know how to write print('Hello World!') in Python and nothing else, then there is a 99.9% chance of you not being able to contribute anything to a potential employees product value.
This is a problem because you will not be able to give anything of value back to your employer.
An employer should know that hiring a newcomer will mean that it takes some time for them to start producing work of value, but it should not be with an unreasonable timeline.
You will need to know the necessary software development skills (programming, architecture, design, etc.) for this not to be a problem.
It will also give you a feeling that you are not contributing and in my experience, that is the worst feeling for a newcomer.
Essentially wait till you are ready to contribute something useful.
As an example, one of the first things I did for a former employer, was to extend the number of programming languages bindings to their library, such that a wider array of developers could use their library.
It was a thing they had wanted to do but never had the time.
It is a reasonably simple task when you know how to do it, so it was put on me to do it.
Therefore, the first task I had, brought value to the company, and I felt like I was contributing, all in all, a win-win for both.
As a counter-example, I worked in a company, where I was thrown into deep-waters, and I had no idea what I was doing.
I had to implement an intranet for the employees of the company, but in a specific framework that, in my opinion, did some weird stuff.
I was unable to find out why it did what it did, and I ended up having to ask too many questions and spend to much time on information search.
In particular, the questions was a problem, because I had to ask developers who were supposed to work on something else, taking time from them and reducing the value they brought to the company.
All in all, a bad situation.
As a side note, the framework was Umbraco. I still to this day have not found out what went wrong.
But I have found out that some configuration has had to be wrong because I have never experienced those issues since.
The second advice is going to contradict the first one a bit. Where you work, you need to learn, and if you do not learn, then you are in the wrong the place. One of the main reasons to be a student programmer is to try out what you learn in school in the real world. This is a learning experience, and you will most likely learn that what you are taught in school is just a foundation to build upon. Now, it takes time to learn, and as a newcomer, there is a pretty good chance you will make mistakes also so bad once. But it is a learning experience, and you need it. Additionally, it is okay if it takes you some time to figure out a problem and how to solve it. Do not expect to solve every problem in 10 minutes. Additionally, if a more experienced developer offers you to pair program or to review your code. TAKE THE OFFER, TAKE IT and soak up everything that the developer tells you. Then afterwards take notes about what you thought was right, what was wrong, and reflect on how you can implement what you have learned into your work.
Finally, do not work at a place that does not have time for you. You will need help getting set up, getting into the project(s), and so on, and you may need help to do so. If there is no time for helping you set up, there is (most likely) no time later for you later, when you have a problem that requires more than one brain. I have seen this a couple of places I have worked (i.e., the Umbraco situation) and it was super challenging for not just student programmers, but also new full-time developers, to get to a state where they were productive. Simply because there was not enough time amongst other developers to get them to a place where that was the case. Which is a huge problem not just for you, but also for the company itself. All companies have crunch times, some have a lot, which is fair. But in those periods they should not hire new employees, it is terrible planing.
In conclusion, it is a good idea to be a student programmer, if you can manage a work-life balance and my advice is that you should be reasonably proficient in coding before starting a job, you should learn from the job, and you should work in a place where they have time for you.
Distributed Denial of Services, Part1 - Introduction & Theory
This blog post is the first in a series of post where I will explain a type of cyber-attack called Distributed Denial of Service (DDoS). The purpose of these post is
- Spread the knowledge of DDoS
- Provide an understanding of what DDoS
- How to perform DDoS
- How to defend against DDoS
- How to make a more sophisticated DDoS attack
The posts will be split into what is DDoS, history/why it is used, theory, execution, and implementation, but I don’t know how many posts yet.
In the end, I will compile all the posts into a single PDF, probably with some editing and with the hopes that it may be able to serve as study-material.
I have to emphasis that conducting a DDoS attack may (we will get into that) be illegal and these post is solely meant for study purposes.
[IMPORTANT:] As I intend to publish this work in the end, you might see me go back and edit these post from time to time, either add, remove, or edit the content.
In this post, I cover what a DDoS attack is, what it has been used for in the past, and the “legality” of DDoS.
What is a Distributed Denial of Service Attack
Almost, since the introduction of computers being connected by networks, there have been cyber-attacks. The purpose of these attacks varies and are very diverse. Within these attacks, there are groups which aim to disrupt a provided service and the access to it, by disallowing access to the service. These are, in general, referred to as Denial of Service (DoS) attacks.
To understand how the DoS work, we must understand what they are trying to do.
When you access a service provided over a network, be it the internet or another network, you are interacting with a form of a web server.
Yes, even if you access a cloud service.
You interact with the service through web request, e.g. HTTP or HTTPS, often using multiple requests to complete a task.
However, it is rarely just you who are interacting with a service, in many cases, millions of people are accessing the same service at the same time, think of of the Google Search site, Facebook, or Twitter.
Now, a web server is just a computer, and it has limited resources, including limits on how many web requests can be served and how many open connections can be maintained. If you exceed these limits, then the computer will either drop a request and not serve it or take a long time to serve it.
This is what a DoS attack takes advantage of, but overloading a web server with a massive amount of web request.
Resulting in some requests being dropped and not served.
This is the basics of DoS attack, what then makes a distributed DDoS attack? Machines are getting increasingly more power they have become able to serve more and more request, and we have developed more complex defence strategies against DoS attacks. This means that it is more challenging to execute a DoS attack using a single machine. Therefore, to increase the chance of an attack to succeed attackers started distributing the attacks such that they where performed from multiple nodes at the same time, increasing the number of possible requests and DDoS was born. Basically, you make all nodes send a request to the same server.
What has DDoS been used for?
Now, we know what DoS and DDoS, what is used for? Well quite frankly, what it says in the attack name. But it can be used for different reasons. The most obvious one is harassment of service with criminal intent. An example is with the purpose to get a ransom for stopping the attacks. This version of DDoS is called Ransom DDOS (RDoS), and groups such as DD4BC and Armada Collective have used this style of attacks in 2015, 2016, and 2017. Radware has this pretty good article Ransomware Attacks: RDoS (Ransom DDoS) On The Rise on this topic. Then there is the “chaos” approach, where DDoS is used to disrupt service for no other reason than “why the heck not”.
Another usage of DDoS is virtual sit-ins protest, which has become an integrated part of Hacktivism. To explain a sit-in is in the physical world a tool used by activist, to block access to a service or building by blocking its access point. It is the same idea of DDoS used as a sit-in just online. Examples of such sit in are well documented, for instance, sit-ins was used against the airline Lufthansa German precedent upholds online civil disobedience
The “legality” of DDoS
So we have a criminal version and an activist version. But is it legal? So I do not know any country where RDoS is legal, and that is for good reasons. But, cases of virtual sit-ins are up for discussion in many countries and have been for some time, if it is activism or not. Germany seems to think it is, while the USA claims it is criminal. So in general it is, you need to check for your self. Sorry, this cannot be stated more precise.
Using Fedora and why
TL;DR: The story of how I found Fedora and why I keep using it.
I have been using Linux on and off, for more than 20 years and the first time I encountered it was on a school machine running Yggdrasil Linux, the first ever paid Linux distribution. Now back then I was used to Window, Dos, and Apple System, so Linux was weird, yet strangely familiar. Already back then Linux and Apple System had things in common, at least Yggdrasil and Apple System. Since that encounter, I only had sporadic meetings with Linux and only used it when at school or in a virtual machine, until 2005. In 2005 I got my first, and only, Windows laptop running Windows XP (good times), but I had no real clue about antivirus software and other security measures, which resulted in 3 months of virus and problems with Avast, AVG, and BullGuard. Additionally I had to reinstall my machine from scratch 2 times in that period. At this point, I hadn’t really touched Linux for roughly 4 years and remember only on systems people had already setup. But I remembered it and that it was more familiar to Apple System. So I started looking and back then Debian was raining king of “easy to install” and I tried it in a virtual machine first and thought what the heck, let us try. So it became my daily drive, dual booted with Windows, as I need Word and PowerPoint for specific tasks and let us be honest at this time OpenOffice sucked. I also had some weird problems with my WiFi card for some reason I never truly figured out and it pissed me off. However, in 2004 a new distribution had seen its birth, Ubuntu, the distro for newbies and back then I was newbie. I happily left Debian behind and jumped at the new shiny distribution. I used for a solid 2.5 years until I went back to Apple and more specifically macOS Leopard 2008 and say what you want Leopard and Snow Leopard was the two best iterations of OS X. However, I had a virtual machine with Ubuntu and I used it almost everyday for some weird task OS X could not do at the time or I had gotten use to a program only available on Linux. Then came spring 2009 and I was asked to make a project for friend, as cheap as possible and as stable as possible. Another requirement was the project had to be done in Java. This gave me the freedom to look outside Windows and the ability to test the project on different operating systems. As I squared the internet for options, a lot of people said Debian or RedHat for servers, for some reason CentOS was never mentioned. I later found out that people back then in general regarded it as a useless toy. But, then I found some who said that for a hobby project RedHat maybe to expensive, so try OpenSUSE or Fedora. I was intrigued, I had heard of OpenSUSE before but never used and Fedora I had never heard of. So I spend some time setting up both servers and a long the way kept strict notes on what I did, the problems I ran into, and how I fixed them. Essentially this was my first lab notebook. Afterwards I compared my notes and came to the conclusion that Fedora had been way easier to setup and trouble shoot, so I went with that. During the process I had also had time to setup both as a desktop system and Fedora had been much easier than Ubuntu, at least for me. So I decided to swap my Ubuntu VM for a Fedora one and here we a decade later and I am still using Fedora, not only as a VM. But also as my main operating system at work.
So why do I keep using Fedora? What is it that keeps me in the blue? Is it the colour? Is it the hat? Is it familiarity? Let me answer two of those really quick, of course it is the hat and not it is not the colour. Familiarity certainly has something to do with it, it is always nice. But it is not my main reason for always returning to Fedora. I actually have a few.
First of yum/dnf vs apt.
One of the reasons, I decided to look for another distribution than Debian and Ubuntu in the first place, was that I had a lot of problems with apt-get at the time often corrupting my system when I did updates.
Which drove me to the brink of insanity and beyond.
It made me hate .deb and apt based distributions for quite a while.
I have only once had similar problems with yum once and that was in Fedora 17.
Now this issue has been fixed in both Ubuntu and Debian and I do use both on servers from time to time today.
Another thing with yum is the command names makes more sense to me and instead of having to use apt-SOMETHING to do a search or install, everything is bundled into one command in yum which I like a lot.
It makes the system must more consistent to use and it is easier to remember commands.
Next Gnome or more precisely Vanilla Gnome. Gnome has for desktops and multi-monitor setups always been my favourite desktop environment. But most distributions, have always add their own sugar. Majaro is in my opinion a horrific example. I want a stock gnome a work my way up from there, I want to enable things not disable things. Also, sorry Majaro/Ubuntu/Other Gnome Theme designers, most of the available themes seems tailored to fit either Mac or Windows users looking to adopt, and neither option often does it well. Therefore it is a huge bonus for me that Gnome comes pretty vanilla in Fedora.
Then we have updating to the next version.
So I usually update to newest Fedora 3 months after its release, just to get the worst bugs that maybe, out of the way.
In the “old days” this meant a clean install.
But today we can use a dnf plugin for system upgrades.
Can be installed like this; dnf-plugin-system-upgrade.
Which makes it super easy to upgrade to the next version of Fedora.
I do need some time to clean up old packages and left over dust from the elder days :p
Now! I do love rolling release and I am envious of ArchLinux and Majaro ease of update.
But this is as good as it gets without being rolling.
Finally and this is actually the big one. Ease of use. For the longest time I recommend Linux Mint to newcomers. It is a good solid distribution and in my opinion better than Ubuntu for newcomers. But since Fedora 30, I actually switched to recommending Fedora. The installation processes of Ubuntu, Mint, and Fedora has become very similar and it is super easy. Even installing third-party non-free drivers is easy. Additionally, when you go to websites for help, the Fedora community has become much more mature and welcoming to newcomers, than we where five years ago. This makes Fedora much more approachable than it use to be. Which means I quickly can get a new PhD student, PostDoc, Sys Admin, developer, or some else dirty quickly without having to babysit the person through the whole process. Increasing both out productivity. I also manage servers for projects and some use RedHat, others CentOS, and again others Fedora Server, and the benefit of having a shared ancestry and close family bond, makes it easy for me to switch between these systems with minimal effort, again increasing productivity.
So these are the reasons I use Fedora and keep on using Fedora. Now I wanna make it clear that I have jumped to other distributions on occasion, I used Manjaro for 2 years, Arch from time to time, Gentoo, and SlackWare. The later still has a very special place in my heart.